What is RAG? A Practical Guide to Retrieval-Augmented Generation for AI Applications
Learn how Retrieval-Augmented Generation (RAG) improves AI applications by combining large language models with real-time knowledge retrieval for more accurate and scalable responses.
Introduction
Large Language Models (LLMs) have transformed how businesses build AI-powered products. From AI chatbots and internal assistants to document search systems and customer support automation, modern AI applications are rapidly becoming part of everyday business operations.
However, traditional AI models have a major limitation: they only know information included in their training data.
This creates several problems:
- Outdated knowledge
- Hallucinated responses
- Limited business-specific understanding
- Inability to access private company data
This is where Retrieval-Augmented Generation (RAG) becomes important.
RAG combines intelligent document retrieval with large language models, allowing AI systems to access external knowledge sources in real time before generating responses.
Instead of relying entirely on pre-trained knowledge, the AI retrieves relevant information first and then generates context-aware answers.
For businesses building AI products, internal copilots, SaaS automation systems, or enterprise AI workflows, RAG has become one of the most practical and scalable AI architectures available today.
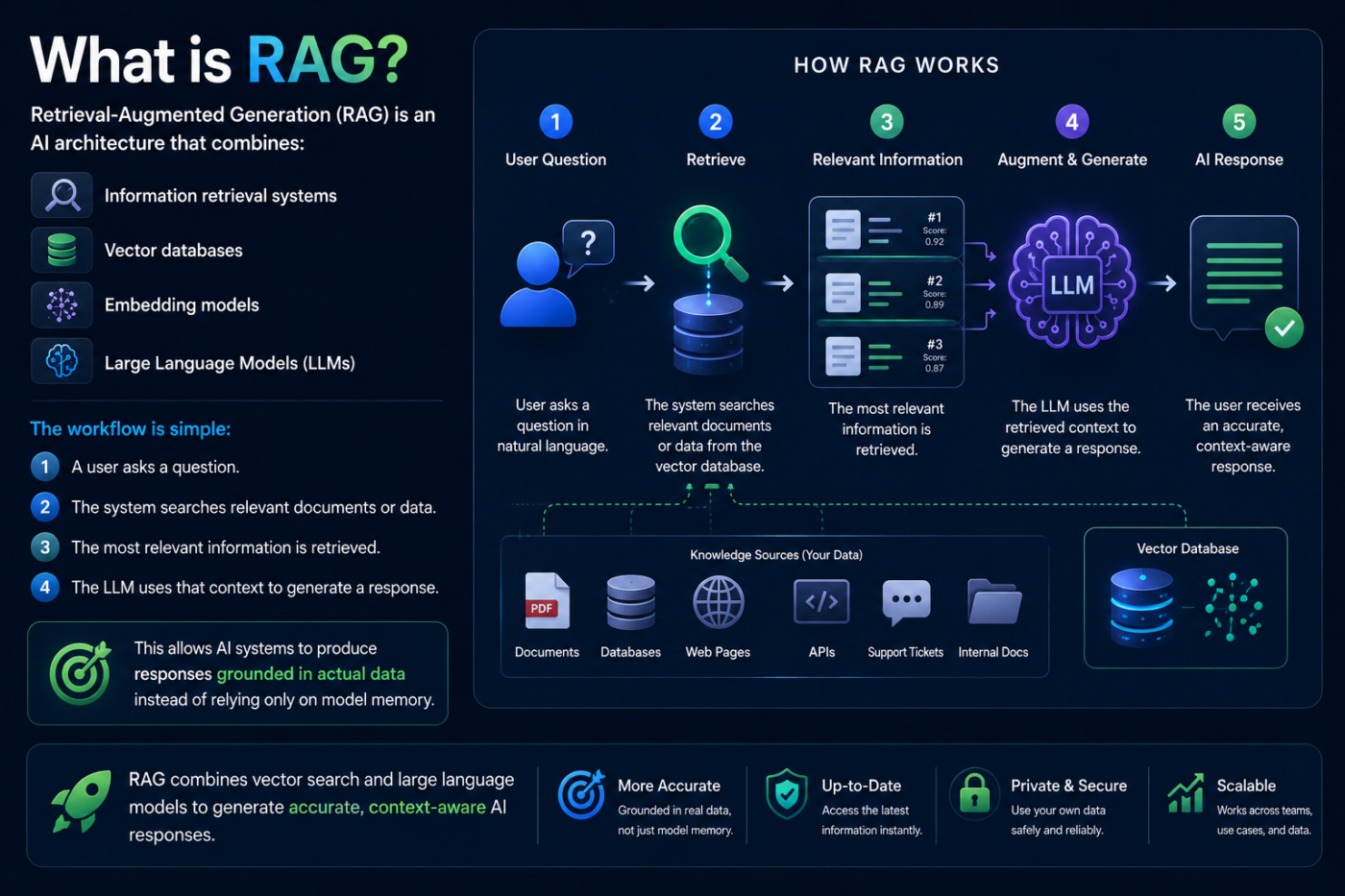
What is RAG?
Retrieval-Augmented Generation (RAG) is an AI architecture that combines:
- Information retrieval systems
- Vector databases
- Embedding models
- Large Language Models (LLMs)
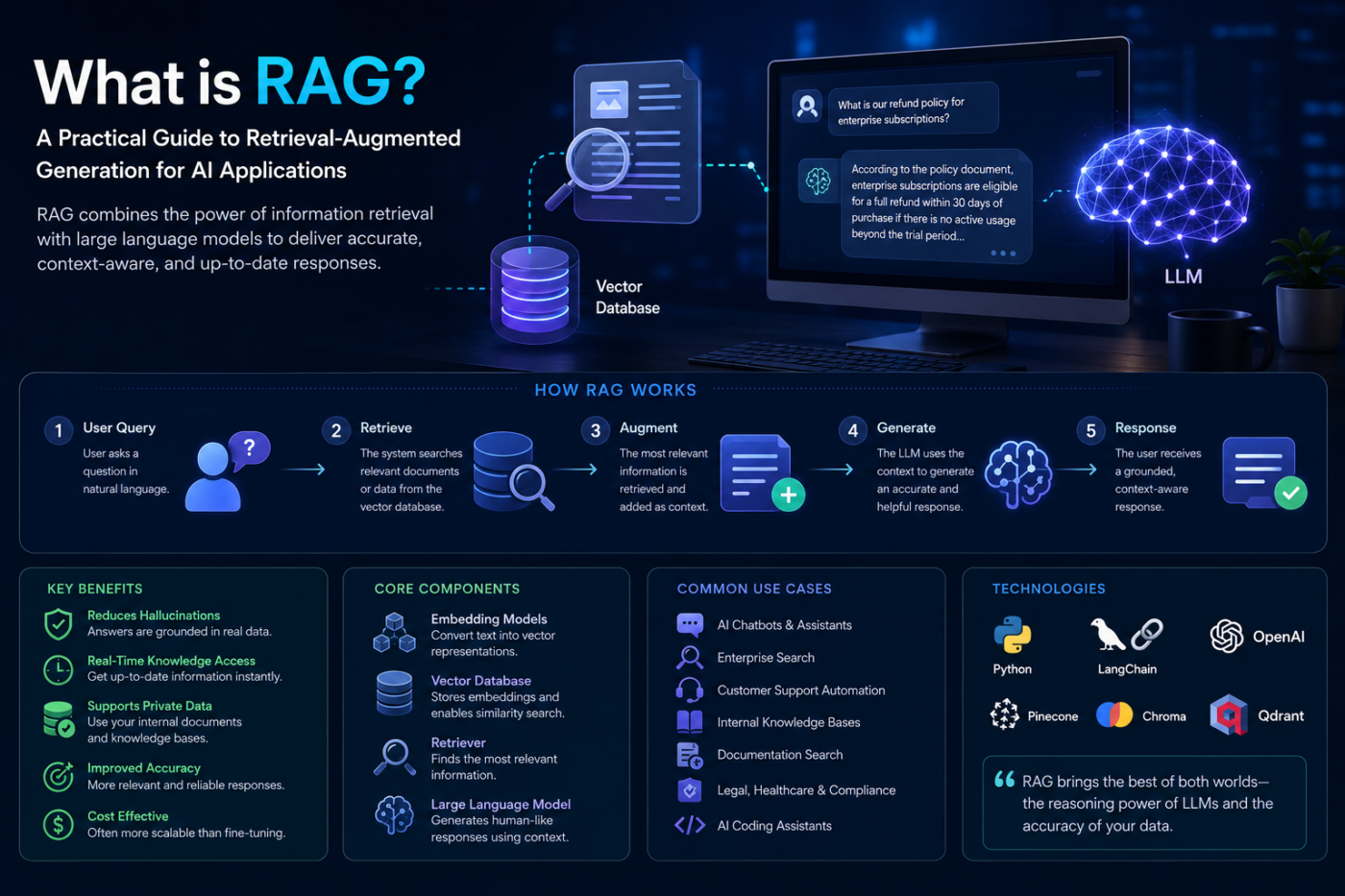
The workflow is simple:
- A user asks a question.
- The system searches relevant documents or data.
- The most relevant information is retrieved.
- The LLM uses that context to generate a response.
This allows AI systems to produce responses grounded in actual data instead of relying only on model memory.
Why RAG Matters
Reduces AI Hallucinations
Traditional AI models sometimes generate incorrect or fabricated information.
RAG reduces this problem by grounding responses in retrieved data sources.
Enables Real-Time Knowledge Access
Businesses constantly update:
- Documentation
- Policies
- Product information
- Support articles
- Internal knowledge bases
RAG systems can retrieve the latest information dynamically without retraining the model.
Supports Private Business Data
RAG allows organizations to build AI systems using:
- Internal documents
- PDFs
- Databases
- APIs
- CRM systems
- Company knowledge bases
This makes AI significantly more useful for enterprise workflows.
Improves AI Accuracy
By providing relevant context before generation, responses become:
- More accurate
- More contextual
- More reliable
- More business-specific
More Cost Effective Than Fine-Tuning
Fine-tuning large AI models can be expensive and difficult to maintain.
RAG often provides a more scalable and practical alternative for many real-world business applications.
How RAG Works
Here’s a simplified RAG workflow:
- Documents are processed and converted into embeddings.
- Embeddings are stored inside a vector database.
- A user submits a query.
- The query is converted into an embedding.
- The vector database retrieves similar content.
- Retrieved context is sent to the LLM.
- The LLM generates a grounded response.
Core Components of a RAG System
Embedding Models
Embedding models convert text into numerical vector representations that AI systems can compare semantically.
Popular embedding providers include:
- OpenAI
- Cohere
- Voyage AI
- Hugging Face models
Vector Databases
Vector databases store embeddings and perform similarity searches.
Popular vector databases include:
- Pinecone
- Weaviate
- Qdrant
- Chroma
- Milvus
- pgvector
Retriever
The retriever searches the vector database for the most relevant information related to a user query.
Large Language Model (LLM)
The LLM generates the final response using the retrieved context.
Popular models include:
- GPT models
- Claude
- Gemini
- Open-source LLMs
Practical Example
Imagine a company with thousands of internal support documents and product manuals.
Without RAG:
- Employees manually search documentation.
- AI chatbots provide generic or inaccurate answers.
- Important internal knowledge becomes difficult to access.
With RAG:
- Employees ask questions naturally.
- Relevant documents are retrieved instantly.
- AI generates contextual responses using company knowledge.
Example query:
“What is our refund policy for enterprise subscriptions?”
The system:
- Searches internal documentation
- Retrieves the relevant policy
- Generates a grounded response
This creates a much more reliable AI assistant.
Basic RAG Workflow in Python
Here’s a simplified conceptual example:
1async def ask_question(query):2 3 # Convert user query into embedding4 embedding = await create_embedding(query)5 6 # Search vector database7 results = await vector_search(embedding)8 9 # Combine retrieved context10 context = "n".join([11 item["content"] for item in results12 ])13 14 # Send context to LLM15 response = await generate_ai_response(16 query=query,17 context=context18 )19 20 return responseVector Search Example
1results = index.query(2 vector=embedding,3 top_k=5,4 include_metadata=True5)Example Embedding Generation
1from openai import OpenAI2 3client = OpenAI()4 5response = client.embeddings.create(6 model="text-embedding-3-small",7 input="What is Retrieval-Augmented Generation?"8)9 10embedding = response.data[0].embeddingUseful AI Development Commands
Install OpenAI SDK
$pip install openaiInstall LangChain
$pip install langchainInstall Pinecone SDK
$pip install pineconeInstall ChromaDB
$pip install chromadbInstall Sentence Transformers
$pip install sentence-transformersRun Qdrant with Docker
$docker run -p 6333:6333 qdrant/qdrantCommon RAG Mistakes to Avoid
Poor Document Chunking
Large or poorly structured chunks reduce retrieval quality.
Good chunking strategies improve:
- Context accuracy
- Semantic relevance
- Retrieval precision
Low-Quality Embeddings
Weak embedding models reduce search quality significantly.
Retrieving Too Much Context
Sending excessive context to the LLM:
- Increases costs
- Reduces response quality
- Adds noise
Ignoring Metadata Filtering
Metadata helps improve retrieval precision by filtering:
- Categories
- Dates
- Departments
- Permissions
No Evaluation Pipeline
RAG systems should be tested continuously for:
- Retrieval quality
- Response accuracy
- Hallucination rates
- Latency
Use Cases for RAG
RAG is widely used in:
- AI chatbots
- Enterprise search
- Customer support systems
- Internal AI copilots
- SaaS automation platforms
- Knowledge management systems
- AI-powered documentation search
- Legal and healthcare document systems
- AI coding assistants
FAQ
Is RAG better than fine-tuning?
For many business applications, yes. RAG is often cheaper, faster to update, and easier to maintain compared to fine-tuning.
Can RAG work with private company data?
Yes. RAG is commonly used with internal documents, databases, APIs, and enterprise systems.
Does RAG eliminate hallucinations completely?
No, but it significantly reduces hallucinations by grounding responses in retrieved information.
What is a vector database?
A vector database stores embeddings and performs semantic similarity searches for AI retrieval systems.
Can small businesses use RAG?
Absolutely. RAG architectures can scale from small internal tools to enterprise AI systems.
Final Thoughts
Retrieval-Augmented Generation has become one of the most important architectures in modern AI engineering. By combining intelligent retrieval systems with large language models, businesses can build AI applications that are more accurate, scalable, and context-aware.
Instead of relying entirely on static model knowledge, RAG allows AI systems to access real-time information dynamically — making AI significantly more practical for real-world business use cases.
At CodeHills, we help businesses design and develop AI-powered applications, automation systems, scalable backend infrastructure, and intelligent knowledge platforms using modern technologies including RAG, vector databases, and large language models.
Ready to turn this idea into a working system?
Share your goals, workflow, or product challenge. We will review the details and recommend the most practical next step.
Discussion
Share your thoughts, questions, or practical experience below.
No comments yet. Be the first to share a thoughtful question or perspective.